들어가며
Web UI 버전은 0.53 2v 버전을 기준으로 작성하겠습니다
기초에서는 세세하게 설명하기보다 간단하게 설명하고 빠르게 그림을 생성 하고 응용하는 법에 대해 설명 하겠습니다
화면의 각 기능에 불명확한 부분 및 어려운 용어들은 심화 부분을 따로 만들어서 시간 날 때마다 업데이트 하겠습니다
간단한 이미지 생성하기
정상적으로 통합 WEB UI를 설치 완료 후 (통합 WebUI설치 바로가기) 127.0.0.1:7860을 URL에 입력하면 Stable diffusion 웹화면으로 이동 합니다
txt2img 탭에서는 사용자가 텍스트를 입력하면 그 텍스트에 맞는 이미지를 만들어줍니다
가장 기본적이면서 Stable diffusion 핵심 기능이기도 합니다
먼저 텍스트 입력 란(이하 프롬프트)에 기초적으로 이렇게 입력되어있습니다
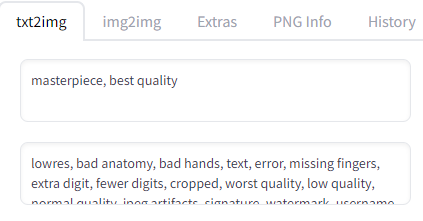
Generate를 클릭 합니다

우측 하단에 이미지가 생성 됩니다
AI 학습 된 모델을 바탕으로 사용자가 프롬프트 입력한 내용대로 이미지를 생성해냅니다 매번 Generate 클릭할 때마다 새로운 이미지가 생성됩니다
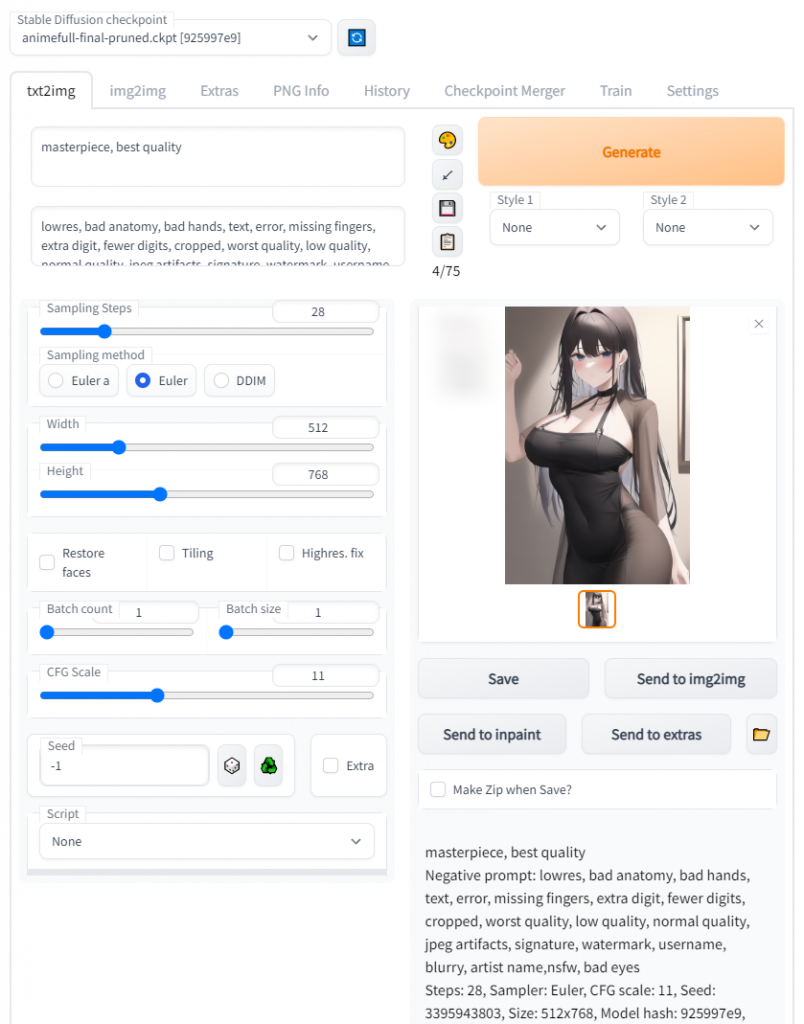
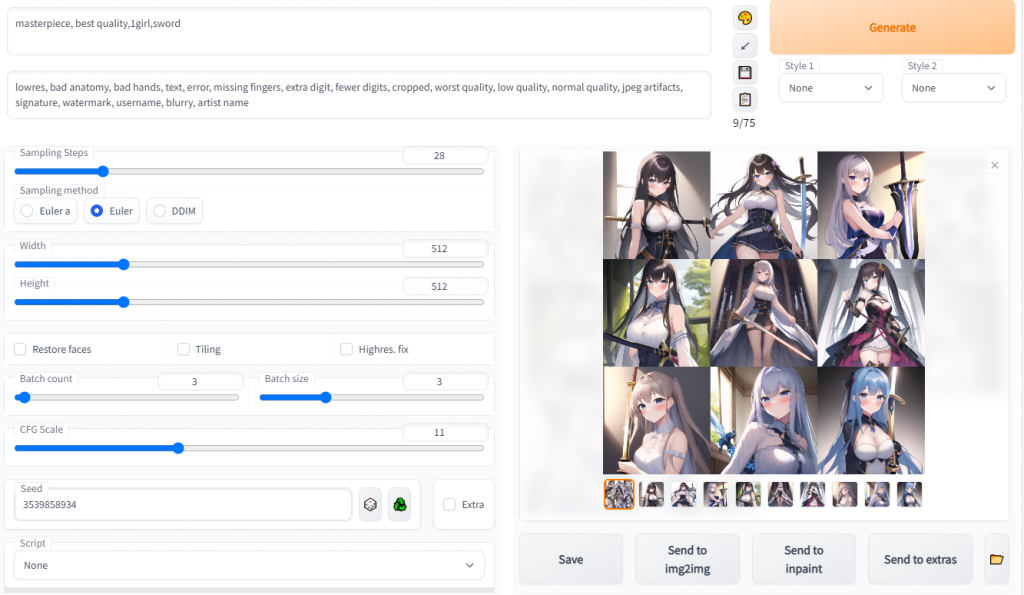
프롬프트에 텍스트 입력하여 이미지 생성하기
그리고자 하는 부분을 상상하여 텍스트를 입력해봅시다
문장으로 입력해도 되고, 단어로 입력해도 됩니다
문장으로 이미지 생성 하기
“고등학교를 다니는 여학생이 길거리에서 웃고 있습니다 ” 예시를 간단하게 입력해보겠습니다
텍스트 입력은 항상 영문으로 입력해야 AI가 이해 가능 합니다
영문으로 번역기를 돌리면
A high school girl is smiling on the street 입니다
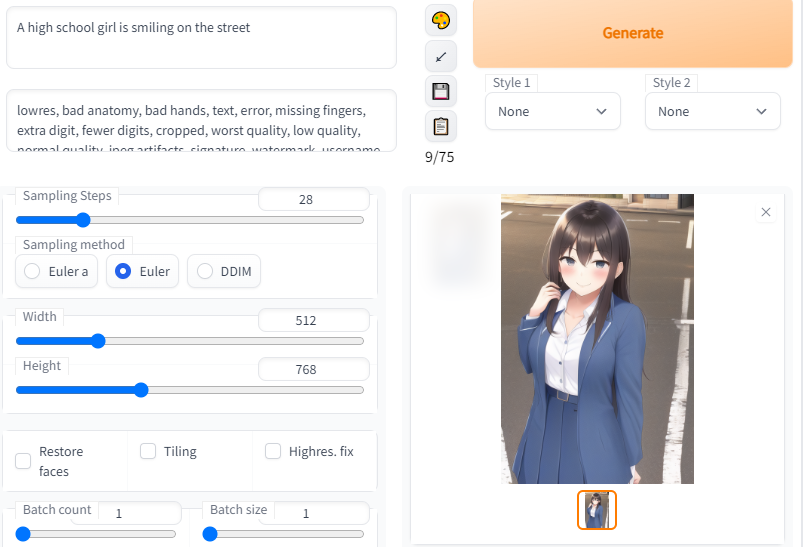
생성이 완료되었습니다 하지만 교복인 지 분간이 어렵습니다 좀 더 문장을 다듬고 세세하게 작성해서 디테일하게 이미지가 만들어지는 것을 확인해봅시다
“고등학교를 다니는 분홍 양갈래 머리와 붉은 큰 눈을 가진 여학생이 길거리에서 웃고 있습니다
그녀는 한 손에 가방을 들고 있고, 세라복을 입었습니다”
를 프롬프트에 입력해봅니다
영문으로 번역기를 돌려보면
“A high school girl with pink ponytail hair and big red eyes is smiling on the street
She is holding a bag in her one hand and is wearing a sailor suit”
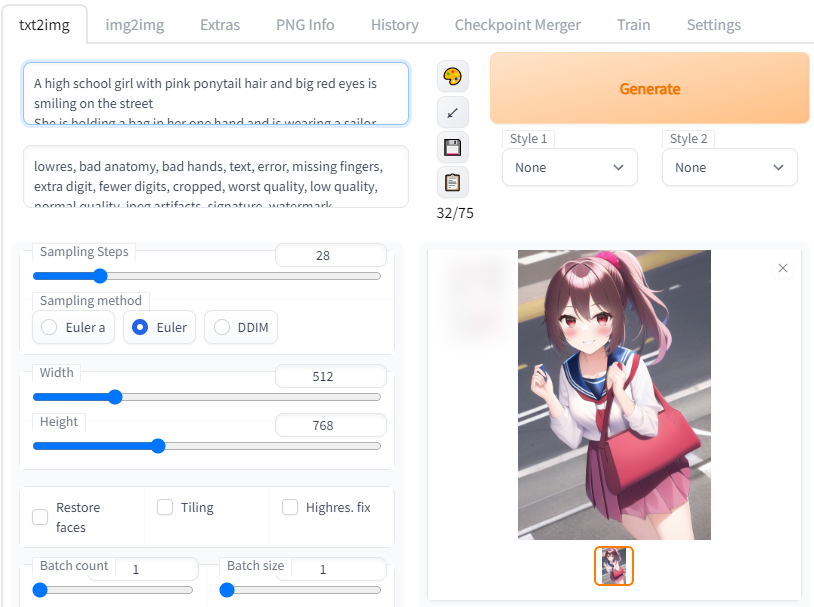
한 번에 이렇게 이미지가 잘 나오지는 않고 여러번 돌리다보면 나옵니다
문장 인식률도 매우 높다는 것을 알 수 있습니다
단어로 이미지 생성하기
단어는 간단하게 생성해보겠습니다
“여자,사무실,넥타이,청바지,서 있다”
영문으로 번역기를 돌려보면
lady,office,necktie,blue jeans,standing
입니다
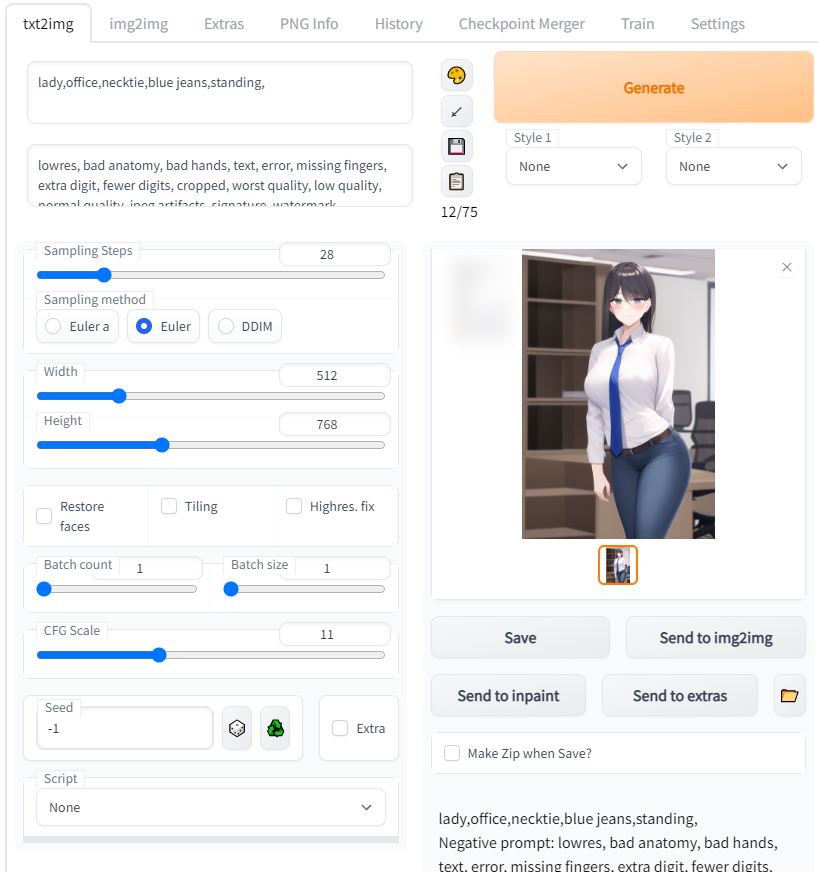
청바지에 어울리는 흰 셔츠를 AI가 선택한 모양입니다
훌륭하게 생성되는 것을 확인 할 수 있습니다
이처럼 문장 또는 단어로 생성이 가능합니다. 상황에 따라서 단어, 문장으로 생성하면 되며 단어 + 문장으로 생성도 가능합니다
하지만 단어와 문장이 길어질수록 AI가 문맥을 파악하기 힘드니 간결하고 정확하게 설명하는 것이 중요합니다
네거티브 프롬프트에 입력하여 이미지 생성하기
지금까지 프롬프트에 단어 또는 문장을 입력하여 이미지를 생성하였다면, 반대로 생성되는 이미지에 나와서는 안되는 아이템을 단어 또는 문장으로 입력할 수 있습니다
위의 단어 예제처럼 흰 셔츠를 입은 여자가 이미지 생성되었는데, 흰 셔츠를 빼고 싶다면 두번 째 입력칸(이하 네거티브 프롬프트)를 입력하면 셔츠 외에 다른 것을 입게 됩니다
셔츠를 네거티브 프롬프트에 등록하고 생성합니다
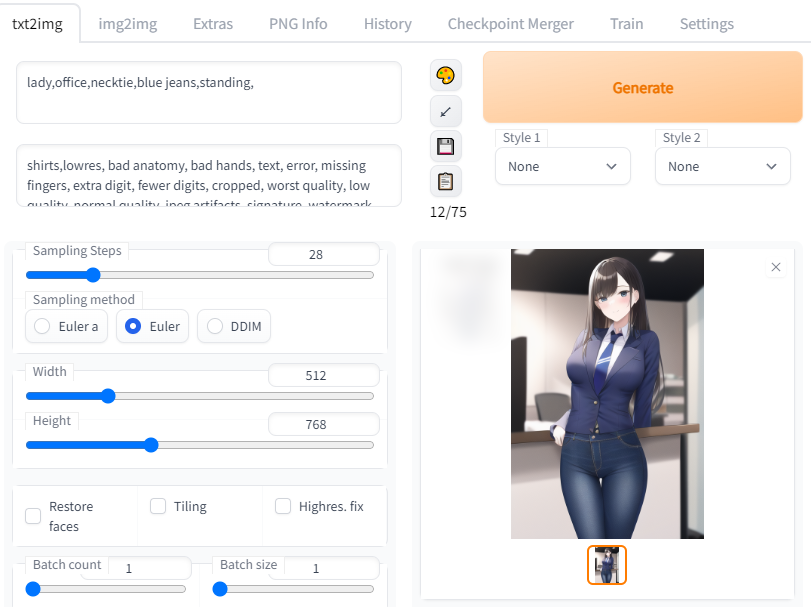
셔츠 위에 다른 옷을 입은 이미지로 변경이 되어 생성됩니다
이처럼 네거티브 프롬프트에 원하지 않는 이미지를 지정이 가능하며, 원하는 이미지를 생성하다가 원하지 않은 이미지가 계속 반복 생성되면 네거티브 프롬프트에 입력하여 차단 할 수 있는 중요한 기능입니다
아래는 자주 쓰이는 네거티브 프롬프트 입니다
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
샘플링 스텝
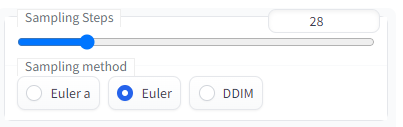
기본 값은 28입니다 샘플링 스텝이 높아질 수록 어떤 변화가 있는지 확인해봅시다

샘플링 스텝 1-21



샘플링 스텝은 AI가 몇 회에 걸쳐 디테일하게 그림을 생성하는지 나타냅니다
샘플링 스텝이 너무 낮으면 그림이 뭉개지고, 그리다 만 것처럼 표현이 됩니다
샘플링 스템이 너무 높아도 사용자의 시각으로는 그림의 차이를 느낄 수 없으며 많은 이미지 생성 시간과 그래픽카드 전력을 많이 사용하게 됩니다
보통 기본 값으로 샘플링 스텝 28을 사용하는 이유이기도 하며, 28으로는 표현이 잘 안되는 프롬프트가 많은 이미지는 값을 높게 조정하면서 디테일하게 표현하는 것이 좋습니다
샘플링 메소드
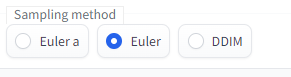
어떤 알고리즘으로 이미지를 생성하는 지 선택합니다
Euler가 기본으로 선택 됩니다

Euler a, Euler, DDIM 알고리즘 비교
알고리즘이 바뀐다고 해서 그림 화풍이 바뀌거나 하는 것은 아닙니다 다만 프롬프트와 샘플링 메소드에 따라서 이미지 제작 속도가 바뀌며, 디테일이 조금씩 다릅니다
원하는 그림이 나오지 않으면 샘플링 메소드를 바꿔봅시다
Width, Height
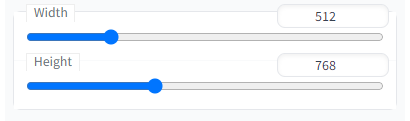
그림 출력물의 가로 사이즈 픽셀과 세로 사이즈 픽셀을 나타냅니다
너무 높게 조정하면 이미지 생성 시간이 오래 걸립니다
세로 이미지 512×768 은 모델이 한 명만 있을 때 주로 사용 되며, 둘 이상의 모델과 풍경이 들어가야 한다면 가로 이미지 1024×768로 변환하는 것이 좋습니다


Restore faces, Tiling, Highres. fix
Restore faces

실사화 이미지 생성 시 얼굴이 자연스럽게 생성되도록 하는 기능입니다
아래 예시 그림에서 2D 이미지에서는 효과가 없는 것을 확인할 수 있습니다


Tiling
이미지를 타일화 합니다 현재로서는 어디에 써야할 지 알려지지 않은 상태입니다 체크 해제하고 사용 바랍니다

Highres. fix
Width,Height의 기본 해상도 512×768 이상 높게 조정하면 프롬프트에 사람을 1명으로 지정하더라도 빈 공간에 사람을 넣는다던가 사물을 배치한다거나 해서 이미지가 원하는대로 나오지 않게 됩니다 Stable Diffusion에서는 기본 해상도 512×512를 넘어가서 빈 공간에는 반드시 뭐라도 그려넣게 됩니다
만약 가로 해상도만 1920이면 사람 세명이 등장할 수도 있습니다 이때 원하는 구도의 고해상도를 얻기 위해서는 해당 옵션을 조정해야 합니다
아래 예시를 보면서 설명하겠습니다 입력 프롬프트는 다음과 같습니다 width는 512~1024 이며 Height는 768 고정입니다
masterpiece, best quality,1girl,sword




마지막 1280×768해상도의 이미지는 가로가 길기 때문에 오른쪽 부분이 남게 되어 빈 부분을 생성하려다보니 이상하게 생성된 것입니다
만약 위의 생성 된 두 번째 768,768 해상도의 이미지를 보다 높은 해상도 1280×1280으로 뽑고 싶을 때 Highres. fix를 사용하는 것입니다
만약 Highres. fix를 사용 안하고 Width,Height 1280×1280을 사용하면 검정 화면만 출력이 됩니다
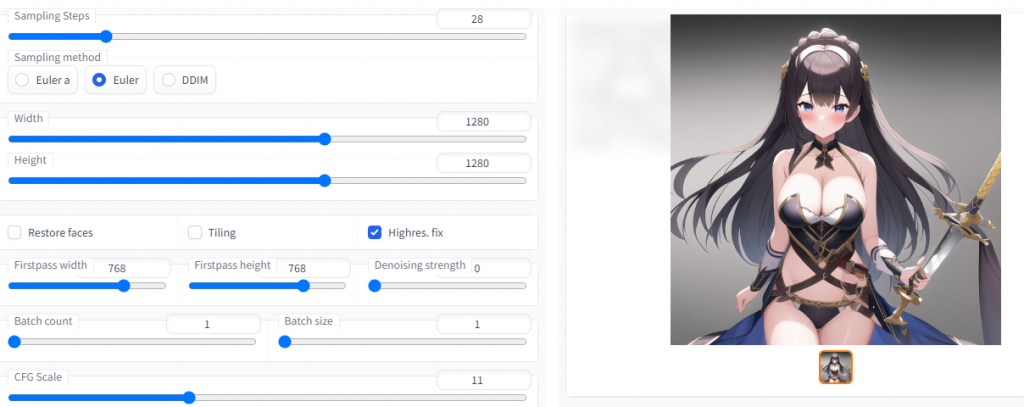
width : 768, height 768 과 동일한 그림이지만, 이미지를 다운 받으면 이미지의 해상도가 1280×1280으로 고해상도 이미지가 생성된 것을 확인 할 수 있습니다
Batch count, Batch size

Batch count는 그림을 몇 번 생성할 지 선택합니다
Batch size는 Batch count를 몇 번 생성 할 지 선택합니다
Batch count X Batch size 는 총 그림의 생성 갯 수 가 됩니다
CFG SCALE
CFG SCALE은 기본적으로 입력 프롬프트의 명령을 얼마나 많이 따를지 선택하는 척도입니다
값이 0일 경우 입력 프롬프트 명령을 수행하지 않고 이미지를 생성하게 되고 이미지 윤곽은 흐리게 됩니다
값이 30일 경우 입력 프롬프트 이상으로 연관 키워드까지 이미지를 생성하게 되고 이미지 윤곽이 강하게 됩니다
샘플링 스텝과 같이 CFG SCALE을 조절하다 보면 원하는 값의 이미지를 생성할 수 있습니다


